Adaptive variables in an algorithm are values used in a calculation that evolve slowly over time to track the behavior of a constant in the formula. When constants are truly constant, then this business of making formulas and performing calculations is easy. We can measure or sense some of the variables in a function with the goal of solving the function. Unfortunately sometimes we are forced to solve multivariate equations even when we cannot supply data for all of the variables. When some of the variables play a greater contribution to the function than others, then we can still solve the multivariate calculation by assuming a constant value for the slower terms in a dynamic function, and then updating those constants slowly over time. Maybe it helps to think of the adaptive variable as changing too fast to be a constant but changing too slow to be a variable.
The rate-of-change of the variables is key in distinguishing the adaptive versus dynamic variables. We could solve our multivariate equation with a constant value for the adaptive variables for a while, but then we need to "tune" the equation occasionally by finding the new values of the adaptive variables that allows us to continue to make accurate calculations again.
The concept of the adaptive variable[]
Adaptive variables have the following characteristics:
- You desire them to be constant in a function so that the function can be solved with other variables
- Can be estimated for initial conditions
- Used to make a prediction, but the prediction can be compared to actual performance of the system later (i.e. by feedback, or closed-loop)
- It's rate of change is very slow compared to the other variables in the formula
In software, we can use a formula to make a prediction based on variables that we can measure fast enough to be true variables and other adaptive variables that we will assume to be constant for now. Later, we can check our prediction with reality, and determine if the value of the adaptive variable was good, and if not good determine the direction that the adaptive variable needs to go to correct the error between the prediction and the reality. In a sense, we are using feedback to adapt the variable to control our calculation of the prediction. Because the rate of change of the adaptive variable is very slow compared to the other variables in the prediction, then we have an under damped control system: it may be horribly under damped and therefore slower than optimal, but it is fast enough for us to make our prediction and still improve the next prediction.
The other concept to understand with adaptive variables is that they adapt slowly and continuously. When an error is found, the adaptive variable will be "nudged" in the direction it needs to go by adding a small delta offset. These small offsets are very powerful because they are learned continuously, or at least very often. A lot of little offsets of course will add up to the larger difference between prediction and reality.
In general the variable will learn in the correct direction. At times, the variable may learn in the wrong direction, but it will not learn very much before being detected and resolved. If the function is well behaved for awhile, then the adaptive variable will learn its true value. If the function is ill behaved, then the adaptation will learn the best average value for the prediction. Our calculation with the adaptive variable will even switch between and/or blend the true value with the best average as the function changes its behavior from behaved to ill-behaved.
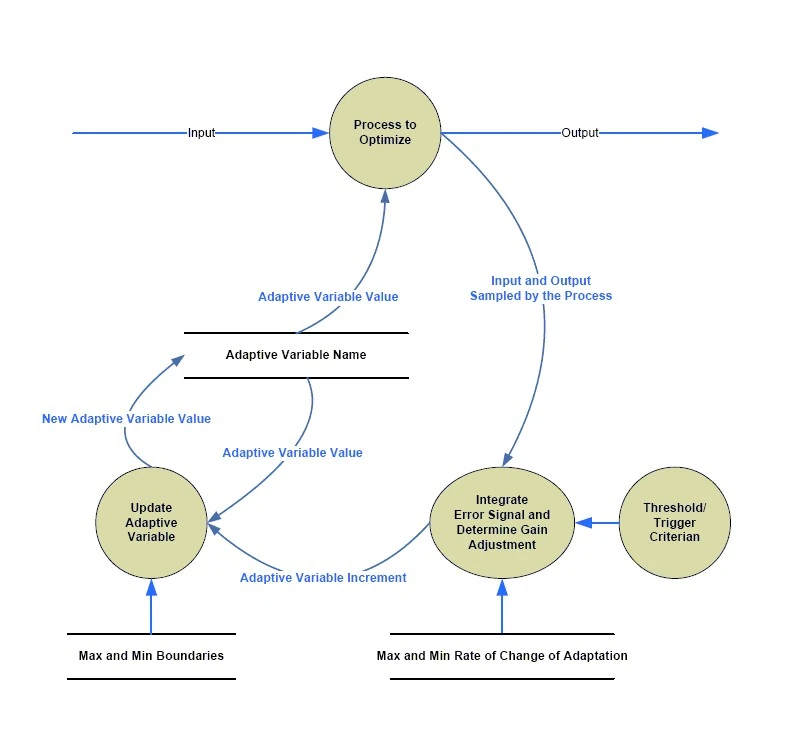
(Cant wait to see an example?: look at the basal rate example).
Side issue: notice how the learning algorithm is not unconstrained. The rate of adaptation is controlled, and so are the limits that the variable can approach in both positive and negative directions. These features mean the adaptation can be "tuned" not only for development and testing, but in the case of an artificial pancreas they would be observable and settable by certified diabetes educators during a patients routine 3-month endocrinology checkup. Some patients may need more aggressive adaptation than others, and some may need more constraint on the boundaries. The adaptive algorithm can still be customized on a case-by-case basis. More about that later.
Having trouble getting a "gut feel" for this concept? It helps to realize that the "Process to Optimize" is making predictions right now, where as the other processes are controlling the "Process to Optimize" at a slower rate. We want to improve the future predictions by evaluating the present predictions and making small modifications to the adaptive variables that we will reuse next time.
Example: the carb-to-insulin ratio[]
As an example of using an adaptive variable, let's consider the calculation of insulin needed to cover a breakfast meal. A diabetic person on MDI will calculate the morning insulin requirement using the carb-to-insulin ratio. This is basically a constant. The variables are the morning blood sugar value (variable and must be measured) and the grams of carbs about to be eaten (variable and also measured). Let's suppose our morning blood sugar is 160 mg/dl (a bit high this morning) but our desired blood sugar target is 110 mg/dl. Our insulin sensitivity factor (another adaptable constant, but more about that later) is 50 mg/dl per unit of insulin. We are going to eat 70 grams of carbs. For this diabetic person, the insulin-to-carb ratio for breakfast (yes, it’s different for meals at different times of the day) is 15 grams per unit of insulin, or simply "15."
Therefore, today's insulin dose is:
[(160-110)/50] + (70/15) = 5.7 units of insulin
(see Insulin pump control variables if you don't understand this math)
After bolusing or injecting this amount of insulin and waiting 3.5 hours (the insulin duration of action), we can then take a blood sugar sample and see how close we came to the target.
Here's the funny thing about the carb-to insulin ratio for breakfast: we used it as a constant to calculate our breakfast insulin, but then we are supposed to look at our BG logbook every week and evaluate that breakfast ratio. Sometimes our blood sugar check after breakfast is high or low because we measured our carbs wrong, or because one day we forgot to give a Lantus injection or change an infusion set. We know to ignore those high blood sugars when evaluating the breakfast ratio. But in the other cases for breakfast in our logbook, we see a pattern wherein after breakfast our blood sugar test is a bit low. We are getting too much insulin in our breakfast dose. We are expected to modify our carb-to-insulin ratio to deliver a little less insulin based on the results in the logbook and use it to improve our carb-to-insulin ratio for next week.
What's this? We used the breakfast carb-to-insulin ratio as a constant value to calculate our breakfast dose every morning, but then later we looked in our logbook to see how the ratio really worked for us to control our blood sugar, and we modified it for future use? Hmmm. Sounds familiar?
Adaptive filtering[]
Now, let’s continue this discussion and consider how to use an adaptive variable in a closed loop control system. We are going to use an amplifier as our summing point for our desired signal and feedback from a sensor. The amplifier will drive the system we want to control, and that amplifier will have some frequency-shaping capabilities to give our control system the stability that is desired. So, technically this summing amplifier is also a filter. Amplifiers have gain, a multiplier that determines how hard we drive the system we want to control. But because the system we want to control may not be a machine, its sensitivity to the driver may vary over time. This is a situation where we want the gain to be an adaptive variable. Thus, a filtering amplifier with an adaptive gain is desired: this is one kind of adaptive filter.
To adapt the gain of our control system, we will use feedback from the system output. This is the same feedback we are already using to close the loop relative to the input, creating in a sense a control loop inside a control loop. This idea may seem distressing, but realize that the relative frequency response of the two loops are vastly different, such that they do not interact. We want the outer loop to behave like an optimized control loop such that the system output will follow the input in a controlled manner. Unfortunately the system response to the amplifier drive is not truly constant, so we want to adapt the gain to track the slow variance in the system response so that the outer loops remains somewhat optimized.

The key to this kind of control is to recognize that we did a prediction based on a model that we have, and then used the feedback to evaluate the actual performance of the model. We can improve upon the model for future use if we modify the model based on past experience.
Once you get a basic grasp of this control concept, it's easy to see how it can be used in several ways to control an insulin pump with CGMS data. When we are able to control the basal rate with the CGMS feedback, we can also learn what the best basal rate (as a function of time of day) should be. If we have a sensor problem, then we can continue to operate in the open loop mode with the basal rate learned from the closed loop mode, i.e. an accurate prediction. When we can't control the basal rate directly because we just bolused for breakfast, we can still use the CGMS feedback to learn the insulin to carb ratio for breakfast (and lunch and dinner). When we have given a correction dose, we can use the CGMS feedback to evaluate the insulin sensitivity ratio that was used to predict how much insulin was needed, and learn that value also.
Wouldn't it be nice to have an insulin pump that adjusts itself -- just as expertly as if your CDE did it for you?
Next[]
Example: how will the algorithm "Learn" the basal rate?
What does it REALLY MEAN to close the loop from the CGMS to the insulin pump?